Decision Tree

- first phrase : condition
- gini : impurity score
- samples : total sample size in this node
- value : [negative sample size, positive sample size]
- Left child : positive, Right child : negative
Impurity
- Gini impurity
gini_impurity = 1 - (negative_class_ratio^2 + positive_class_ratio^2)
- Entropy impurity
entropy_impurity =
- negative_class_ratio * log2(negative_class_ratio)
- positive_class_ratio * log2(positive_class_ratio)
- Information gain
information_gain =
parent_impurity
- (left_child_sample_size / parent_sample_size) * left_child_impurity
- (right_child_sample_size / parent_sample_size) * right_child_impurity
- The decision tree model will maximize information gain in each node.
Python code
Get in mind that I'm using...
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
data, target, test_size=0.2, random_state=42
)
First Decision Tree Classifier Model
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(x_train, y_train)
dt.score(x_train, y_train), dt.score(x_test, y_test)
>> (0.996921300750433, 0.8592307692307692)
Visualization
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()

plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
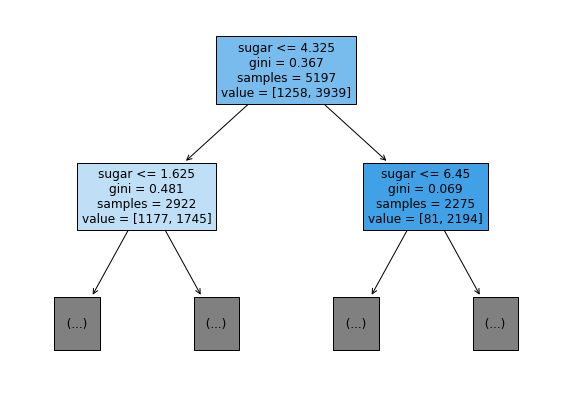
max_depth
- limit decision tree depth
- will be less efficient
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(x_train, y_train)
dt.score(x_train, y_train), dt.score(x_test, y_test)
>> (0.8454877814123533, 0.8415384615384616)
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()

Feature importance
dt.feature_importances_
>> array([0.12345626, 0.86862934, 0.0079144 ])

